
Datengetriebene Automation, das ist das Thema, das Alin Kalam in seiner Rolle in der Lufthansa Group und bei den Austrian Airlines befasst. Wir haben den begabten Musiker, studierten Astrophysiker und Data Science Evangelisten gefragt, was es braucht, um aus den Datenschätzen im Unternehmen wirkliches Geschäft zu generieren, was sich denn eigentlich wirklich hinter der Rolle des Data Scientist verbirgt und wie IT und Fachabteilungen gemeinsam dabei Erfolg haben können, datengetriebene Geschäftsmodelle zu entwickeln.
-
Warum NoOps eine Voraussetzung für den Erfolg datenrelevanter Initiativen sind – aber DevOps besser als gar kein Ansatz ist
-
Wie man aus den Datenschätzen des Unternehmens auch wirklich Umsatz machen kann
-
Was bei Unternehmenskultur und Rollenverteilung eine Rolle spielt

Wieviel Geschäftspotenzial steckt tatsächlich in den Datenschätzen des Unternehmens? Wie können sie genutzt werden?
Das ist natürlich zwischen Großunternehmen & KMUs differenziert zu betrachten. Die sog. „Legacy Corporates“, also traditionsreiche Großunternehmen, sitzen nach wie vor auf große Mengen an Daten und machen bspw. aus Ressourcengründen relativ wenig daraus. Ganz anders schaut das im Innovationsumfeld von KMUs / Start-ups, die oft mit der Datenfrage beginnen und aus Kostengründen gleich geordnet und aufbauend agieren ohne die Daten nur einfach zu sammeln. Dieser Art von Flexibilität fehlt oft in den Großunternehmen und genau dadurch ist der Begriff „Dark Data“ entstanden.
Unter „Dark Data“ versteht man Informationsressourcen, die Organisationen während regulärer Geschäftsaktivitäten sammeln, verarbeiten und speichern aber im Allgemeinen, aus welchen Gründen auch immer, nicht für weiterführende Zwecke verwenden können (z. B. Analysen, Prozessoptimierungen etc.). In der Finanzwelt speichern Unternehmen häufig nur zu Compliance-Zwecken. Das Speichern und Sichern von Daten verursacht normalerweise mehr Kosten (und manchmal ein höheres Risiko) als der Wert so die Meinung vieler „Legacy Corporates“, was natürlich holistisch betrachtet nicht richtig sein kann.
Genaue Prozentzahl weiß natürlich keiner, aber laut einer IBM Studie aus dem Jahr 2018 sind über 80% aller vorhandenen und gesammelten Daten von Großunternehmen „Dark Data“ und oft auch unstrukturiert. Die Studie sagte auch voraus, dass diese Zahl bis Ende 2020 sogar auf 93% steigen wird.
Was waren bisher die Show Stopper dabei, die Möglichkeiten für Big Data und Analytics auszuschöpfen?
Aus den Erfahrungen der letzten Jahre habe ich die objektive Meinung, dass folgende Punkte sehr kritisch sind:
-
- Data Handling: Oft fehlt es an optimierten Lösungen, die mit den klassischen IT- & Datenarchitekturen gut zusammenarbeiten. Die proprietären Lösungen aus diesem Umfeld (bspw. aus der Big Data Welt) tragen sehr viel zur der Sache bei. Nichtsdestotrotz stelle ich immer wieder fest, dass Data Storage, das große Thema der vergangenen 10-15 Jahre, mittlerweile sehr gut bedient ist und für viele nicht nur erschwinglicher- sondern auch lösbar geworden zu scheint.
- Data Management: Nach wie vor einer der größten Herausforderungen, die u.a. auf Problematiken von Data Handling aufbauen. Zudem gibt es meistens eine Fülle an historischen Daten- & IT Systeme (sog. Legacy IT), die mittlerweile Themen rundum Master Data (Stammdaten) gut regeln. Jedoch mit der fast exponentiellen Zunahme von Datenerfassung/Sammlung ist das Thema „Metadada Management“ (Daten über Daten) weiter ziemlich ins Rampenlicht gerückt. Denn oft kristallisieren sich die neuen- unentdeckten Wissensschätze heraus wenn man die Metadaten im Gesamtkontext in Datenmodellen verwendet. Hierbei etablieren sich die gängigen Herangehensweisen/Tools etc. erst langsam am Markt. Es gibt sehr viel Aufholbedarf, denn große Mengen an maschinell erzeugten Daten (bspw. üblich in der Luftfahrt) können erst dann verarbeitet werden, wenn Metadaten für Modellierungen etc. mitverwendet werden.
- Compliance & Allgemeinte Investitionssituation: Neuerlich kommen leider auch Krisenbedingte Aspekte hinzu. Unternehmen, die das Thema Daten nicht im Fokus hatten, werden es wahrscheinlich jetzt noch schwerer haben. Die allgemeine Situation wird durch die Covid Pandemie noch prekärer. Zudem kommen sehr hohen Auflagen bzgl. Datenschutz etc. dazu, wodurch viele es am ehesten sein lassen. Nichtsdestotrotz haben viele die Compliance-Agenden & Datenschutzauflagen in den letzten Jahren weniger als Hürde-, sondern als Chance entdeckt! Weil in Compliance sowieso gezwungenermaßen Gelder investiert werden müssen, verfolgen viele die Strategie: „wenn man Dinge sowieso machen muss, macht man es gleich richtig und hat am Ende sogar einen Marktvorsprung“.
Wie sieht dabei die Rollenverteilung von IT und Business aus? Wie sehr kann der Anwender mitgestalten?
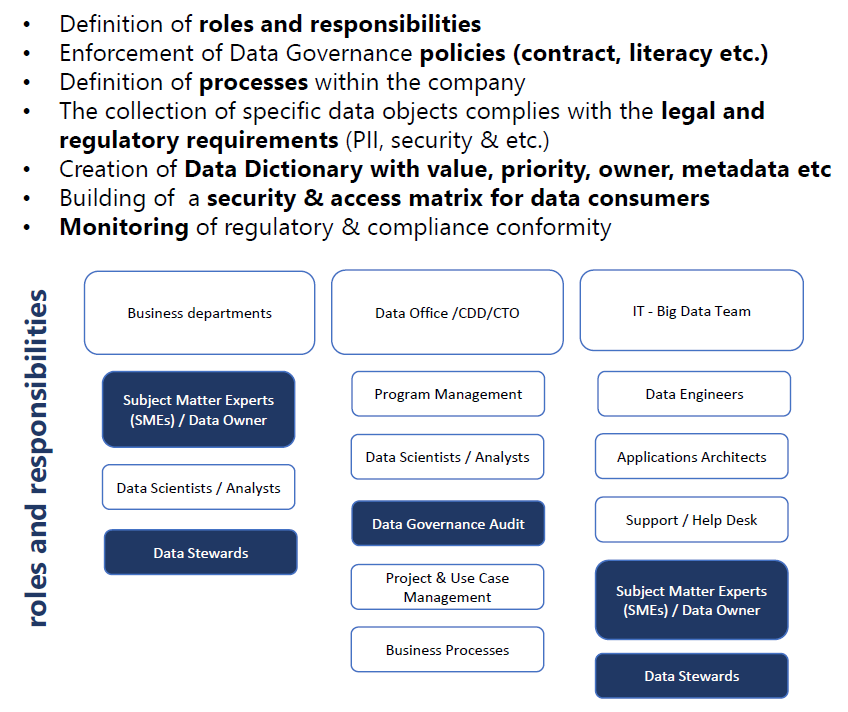
Für mich ist es absolut sichtbar, dass viele Organisationen es leider noch nicht geschafft haben die klassischen Denkschemas & alteingesessenen Organisationsstrukturen in modernen Arbeitsweisen im Datenumfeld einzubetten. Somit fehlen zwischen IT & Business oft eindeutige Rollen von Data Owner (Wer besitzt organisatorisch die Daten XY und hält für die richtige Interpretation seine Hand ins Feuer?), Data Steward (Wer pflegt die Daten richtig ein bzw. sorgt für die Qualitätssicherung wenn diese Aufgabe primär automatisiert durch IT Systeme gemacht wird?), Data Architect/Engineer (Wer harmonisiert die Daten und stellt die technische Verbindungen in den Produktionssystemen her?).
Hierbei wird es auch sofort beinhart sichtbar, welche Organisationen sich tatsächlich sinnvoll mit Daten beschäftigt und wer das Thema nur, sagen wir mal, aus Kosmetikgründen stiefmütterlich behandelt!
Aber nach den letzten Umbruchsjahren kann man heute sagen, dass das Thema „Daten“ mehr denn je im Businessbereich angekommen ist. Das heißt, viele relevanten Themen rundum Governance & Rollen sehr oft aus Business vorangetrieben- und gemeinsam mit der IT im Gesamtbild gesetzt werden damit aus einem eine „Data-driven“ Organisation wird. Folgende Punkte und Herangehensweisen waren für mich immer nützlich. Es empfiehlt sich dabei ein gemeinsames Vorgehen zwischen IT & Business:
Copyright: Alin Kalam
Wie ist dabei die Rolle der Data Scientists? Was sind die Voraussetzungen für ihre Arbeit?
Die Rolle „Data Scientist“ ist überwiegend im Business zu finden. Die Personen ist auch heute einer Art Allrounder die, nicht nur Daten analysieren-, Datenmodelle erstellen-, & diese auch in Kontext setzten können, sondern auch eine starke Vermittlerrolle einnehmen.
Jedoch die Arbeitsweise hat sich in den letzten Jahren ziemlich weiterentwickelt in dem mehr Standardisierungen (Architektur, Tools etc.) da sind. Auch zeigt es sich sehr stark an, dass gewisse systematische Tätigkeiten wie Datensäuberung, Harmonisierung, die noch immer fast 75% der Arbeitszeit konsumiert, qualitative- maschinelle Unterstützung bekommt.
Beim automatisierten „Maschine Learning“ (AutoML) wird bspw. im Wesentlichen der End-to-End-Prozess der Anwendung des maschinellen Lernens auf reale Probleme automatisiert. Das ist oft eine qualitative Unterstützung für den Data Scientist. Dabei werden viele Arbeitsschritte wie maschinell unterstützte Kategorisierung von Daten, Entdeckung und Ausmerzung von Fehlern etc. mit Klickgeschwindigkeit erledigt. Alles in Allem werden die kommenden Jahre sehr viel Überraschung und positives parat halten, wenn selbst „The Sexiest Job“ bis zu einem gewissen Level mehr und mehr Automatisiert wird! Das positive daran ist, dass diese Hilfen bei den Data Scientists hoch angesehen- & sehr willkommen sind. Selten habe ich in meiner Laufbahn Datenspezialisten getroffen die zu wenig zu tun hatten. Genau gesagt das Gegenteil ist der Fall und hier helfen natürlich jede auch so kleine maschinelle Unterstützung durch Tools, Tricks & Tipps.
Welche Anforderungen ergeben sich an die Daten-Infrastruktur?
 Es gibt ja mehrere etablierte Ansätze von Datenarchitekturtypen wie Lambda & Kappa, die für unterschiedlichen Anforderungen gut sind. Interessant ist jedoch, dass man mehr und mehr vermeidet Analytics, Architektur, Governance etc. differenziert zu betrachten- sondern nun endlich von sog. „Data Ecosystem” ausgeht.
Es gibt ja mehrere etablierte Ansätze von Datenarchitekturtypen wie Lambda & Kappa, die für unterschiedlichen Anforderungen gut sind. Interessant ist jedoch, dass man mehr und mehr vermeidet Analytics, Architektur, Governance etc. differenziert zu betrachten- sondern nun endlich von sog. „Data Ecosystem” ausgeht.
Ein Datenökosystem wird somit eine Sammlung von Infrastrukturen, Analysen und Anwendungen, mit denen Daten erfasst und analysiert werden statt nur für zweckgebundene Vorhaben (Use Cases) neue Technologien zu implementieren. Das Thema Daten wird dadurch noch holistischer, weil die alten Legacy Systeme in die Rente geschickt werden so und ganze Datenlandschaften neue entstehen können. So versuchen die großen Unternehmen aus der Welt der kleinen qualitative- & positive Beispiele abzuschauen um sich für die Zukunft richtig aufzustellen. Das erhöht gleichzeitig die Chance aus den Unmengen von Dark Data wegzukommen und mit wenig Kosten/Ressourcen in Start-up Manier die Datenwelt aufzustellen.
Und wie sehen die technischen Anforderungen aus? Welche Tools und Infrastruktur sind erforderlich?
Aktuell betrachte ich das Konzept von „NoOps“ als einer der wichtigsten Voraussetzungen für datenrelevante Entwicklungen. NoOps (No Operations) ist ein Konzept, wonach die IT soweit automatisiert und von der zugrunde liegenden Infrastruktur abstrahiert wird, sodass kein spezielles Team mehr für Produktionspflege & Instandhaltung von Datenmodellen benötigt wird. Somit verschwindet einmal mehr die Barriere zwischen IT & Business in Sachen Datenverarbeitung. Wenn man solche Herangehensweisen obendrauf mit Governance & Rollen verbindet, fallen weiter mittel- oder langfristige Show Stopper aus der Liste.
Grundsätzlich gilt für mich meine These: „Im Zweifelsfall lieber DevOps als irgendetwas“. Das heißt Organisationen wären besser dran, wenn sie im ersten Schritt eine DevOps implementiert haben als ein Mischmasch und Unübersichtlichkeit zwischen Research/Development & Operation. Ohne DevOps oder NoOps mag es im klassischen Softwareumfeld bei kleineren Unternehmen vielleicht irgendwie funktionieren aber es ist in letzter Zeit mehr als unumgänglich für Datenverarbeitung geworden.
Confare CIO Summit 2020
Österreichs größtes IT-Management Forum
Use Cases, Insights, Meet-Ups, Chats & Austausch auf Augenhöhe.
Workshops zu Topics wie Agiles Management, Cybersecurity, Leadership, AI Innovation, Fehlerkultur und IT & OT mit voestalpine, Red Bull, STEYR Arms, Porsche Informatik, Stadt Wien uvm.
*Für CIOs und IT-Manager ist die Teilnahme mit keinen Kosten verbunden
Wenn Data geschäftlich an Bedeutung gewinnen, was bedeutet das für die Sicherheitsanforderungen? Wo gibt es hier Handlungsfelder?
Das gute dran ist, dass die hohen Sicherheitsanforderungen in Europa aufrechterhalten bleiben und gar mit ethischen Aspekte weiterentwickelt werden! Das bietet im Gegensatz zu den anderen Regionen der Welt hohe Sicherheitsstandards wofür einheimische Unternehmen stehen können. Gerade in der Covid-Krise sieht man welchen Stellenwert anonymisierte Daten im sog. „Contact Tracing“ Umfeld funktionieren können! (Stichwort: Corona App). Da hat sich die Theorie „Andere Länder wie China, Russland ohne jegliche Datenschutzmechanismen haben einen Vorteil, weil sie keine EU Auflagen erfüllen müssen“ absolut als falsch bewiesen.
Kurz vor der Covid-Krise am 19. Februar hat die Europäische Kommission die umfassende Datenstrategie der kommenden Jahre bekanntgegeben. Darin steht, dass der europäische Datenraum Unternehmen in der EU die Möglichkeit geben, sich die Größe des Binnenmarkts zunutze zu machen. Gemeinsame europäische Vorschriften und wirksame Durchsetzungsmechanismen sollten gewährleisten, dass
-
- Daten innerhalb der EU und branchenübergreifend weitergegeben werden können,
- die europäischen Vorschriften und Werte, insbesondere in Bezug auf den Schutz personenbezogener Daten, das Verbraucherschutzrecht und das Wettbewerbsrecht uneingeschränkt geachtet werden,
- die Regeln für Datenzugang und Datennutzung gerecht, praktikabel und eindeutig sind und es klare und vertrauenswürdige Mechanismen für die Daten-Governance gibt, offen, aber bestimmt und auf der Grundlage europäischer Werten mit dem internationalen Datenverkehr umgegangen wird
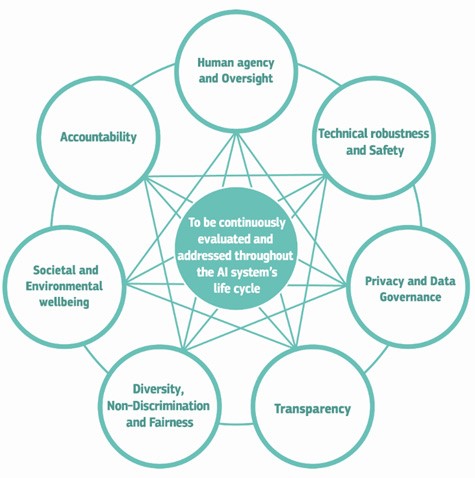 Als Fundament wird hierbei die Regelungen der letzten Jahre herangezogen wie die DSGVO oder Cybersecurity Certification Framework (ICCF). Die sog. „Ethics guidelines for trustworthy AI“ ist beispielsweise ein weiteres fundamentales Werk mit klaren ethischen Vorgehensweisen um Lösungen im Umfeld von „Artificial Intelligance“ voranzutreiben. Das ist natürlich sehr wichtig und relevant für großflächige Datenauswertung und Generierung von intelligenten Businesslogik/Automatisierungen, denn im Zentrum von KI Lösungen stehen nun mal Daten.
Als Fundament wird hierbei die Regelungen der letzten Jahre herangezogen wie die DSGVO oder Cybersecurity Certification Framework (ICCF). Die sog. „Ethics guidelines for trustworthy AI“ ist beispielsweise ein weiteres fundamentales Werk mit klaren ethischen Vorgehensweisen um Lösungen im Umfeld von „Artificial Intelligance“ voranzutreiben. Das ist natürlich sehr wichtig und relevant für großflächige Datenauswertung und Generierung von intelligenten Businesslogik/Automatisierungen, denn im Zentrum von KI Lösungen stehen nun mal Daten.
(Copyright: Europäische Kommission (Öffentlich))