
Alin Kalam ist als Big Data Officer bei der BAWAG P.S.K. federführend bei den Big Data Initiativen der Bank. In seinem Vortrag bei der Confare Konferenz IDEE 2018 berichtet er darüber. Im Vorfeld haben wir ihn gefragt, wie es um die digitale Transformation in österreichischen Unternehmen steht und was hinter dem Hype tatsächlich an Business Potenzialen entstehen.
Worin liegt die Bedeutung von Big Data Ansätzen im Zusammenhang mit der Digitalen Business Transformation?
 Für mich ist die digitale Transformation ohne passende Datenverarbeitungstechniken wie Machine Learning, Data-Mining usw. gänzlich unvorstellbar. Weil aber Investitionen in relativ unbekannte Technologien aus diesem Umfeld immer mit einer gewissen Herausforderung & Risiko zusammenhängen, wird bspw. seit Jahren im Großraum DACH viel diskutiert, aber wenig unternommen. Also wird Big Data immer wieder als Buzzword auf die lange Bank geschoben und das wiederum ist ein Beweis für die Kurzsichtigkeit vieler Managementetagen. Europa hat deshalb im Vergleich zu USA, China & sogar Indien ein riesen Aufholbedarf in Weiterentwicklung, aber auch Anwendung von Big Data Technologien.
Für mich ist die digitale Transformation ohne passende Datenverarbeitungstechniken wie Machine Learning, Data-Mining usw. gänzlich unvorstellbar. Weil aber Investitionen in relativ unbekannte Technologien aus diesem Umfeld immer mit einer gewissen Herausforderung & Risiko zusammenhängen, wird bspw. seit Jahren im Großraum DACH viel diskutiert, aber wenig unternommen. Also wird Big Data immer wieder als Buzzword auf die lange Bank geschoben und das wiederum ist ein Beweis für die Kurzsichtigkeit vieler Managementetagen. Europa hat deshalb im Vergleich zu USA, China & sogar Indien ein riesen Aufholbedarf in Weiterentwicklung, aber auch Anwendung von Big Data Technologien.
Zudem wird auch seit langem über die bevorstehende Transformationswelle gesprochen und dennoch hat jeder eine eigene Meinung bezüglich Digitalisierung. Da die Industrie auf europäischem Boden ohnehin relativ automatisiert ist, wollen viele unter Digitalisierung überwiegend Kostenreduktion durch Optimierungen oder die digitale Aktivierung vom Kunden verstehen. Das ist meiner Meinung nach grob fahrlässig, weil moderne Kunden zunehmend anspruchsvoller werden und neben digitalen Dienstleistungen auch erstklassige Beratung, Services etc. im „Omnichannel“ benötigen. Digitalisierung ist also nicht nur Kostenreduktion, sondern ein funktionierender Zusammenschluss vieler Komponenten mit Hauptaugenmerk auf Online und sinnvoller Automatisierungen dahinter – damit weiterhin trotz der Schnelllebigkeit unserer Gesellschaft langfristige Kundenbindung etc. gelingt.
Die Gewinner der anhaltenden Transformationswelle werden all jenen sein, die ihr Geschäftsmodell und ihre Produkte als Technologie Anbieter weiterentwickeln, kontinuierlich anpassen und am Ende des Tages stärker denn je auf die soziale Komponente, Emotionen & Menschlichkeit, setzen. Also Dinge, die auch im 21. Jahrhundert höchstwahrscheinlich nicht von Computern optimal abgedeckt werden können. Und damit das klappt, wird die Datenverarbeitung in Form von Big Data Analytics/ Data Science und die dazugehörige IT-Architektur einer der Kernelemente aller kunden- & effizienzgetriebenen Entwicklungen der kommenden Jahre sein. Denn Faktum ist, dass die Datenerhebung- & Haltung in nächster Zeit quer durch aller Branchen weiterhin beinahe exponentiell zunehmen wird!
Wo gibt es konkrete Anwendungsbeispiele?
Nachdem sich das vermeintliche Buzzword Big Data in den letzten Jahren schrittweise demystifiziert hat, können mehr und mehr Unternehmen auf ausgereifte Technologien und Konzepte setzen, die sich in der Praxis bereits bewährt haben. Zwar etwas verspätet, jedoch trotzdem irgendwie gerade noch rechtzeitig, ist Big Data bereits ein Thema für die europäische “Mainstream Wirtschaft”. Für alle Einsteiger stellt sich zunächst die Frage, ob ihr Unternehmen für die Zukunft gut gerüstet ist. Dazu gehört aus meiner Sicht logischerweise etwas wie „Digital/Big Data Roadmap“ und eine strategische-, organisatorische- aber auch technische Mindestaufstellung, um die Transformation aus allen Ecken voranzutreiben.
Abseits davon geht die fieberhafte Suche nach Business Cases, Projekten rundum solcher Vorhaben ununterbrochen weiter, während die einfache Praxis zeigt, dass die sog. „low hanging fruits“ eine optimale Einstiegsmöglichkeit ohne großartige Hürden anbietet, weil diese Fragestellungen bereits eine gewisse Reife und erfolgsversprechen beinhalten. Das kann bei einer Retail Bank eine neue berechnete Kaufwahrscheinlichkeit, oder sogar Kundenabwanderungsanalysen sein. Je nach Organisation- & Technologiereife kann dieser Schritt nach Bedarf optimal gewählt werden.
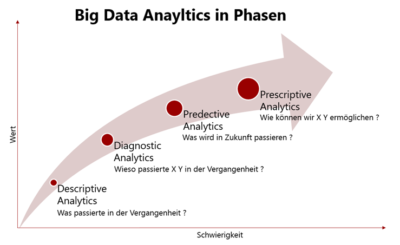
Nach oder während dieser Phase sollte man sich ausführlich Gedanken über Themen wie Big Data Lake oder neuere Konzepte wie „Big Data as a Service“ machen, damit die technische Umgebung für Analytics/Data Science optimal implementiert werden kann. Unabhängig davon stehen üblicherweise, wie so oft vernachlässigte Hausaufgaben in Bereichen wie Prozesse, Data Governance, Data Quality & etc. an und wenn eine ganzheitliche datengetriebene Digitalisierungsstrategie verfolgt werden soll, müssen gute Lösungen für diese Fragen gefunden werden.
Sehr beliebte Anwendungen stammen immer wieder aus Marketing & Salse Bereichen, weil hier Kundendaten bereits existieren oder relativ leicht zusätzliche Daten erhoben werden können. Dabei werden fast immer relevante Fragestellungen/Use Cases angegangen wie „next best offer“ (BSP: Kunden die x gekauft haben, kauften auch y im Online Kanal).
Sonst gibt es sehr viele Anwendungsbespiele aus Risk, Security oder Betrugsbekämpfung, wo unstrukturierte Daten wie Texte, Bilder, Videos etc. eine maßgebliche Rolle spielen und Big Data erst richtig zum Zug kommt. Wenn aber solche Projekte/ Use Cases bereits mit anderen herkömmlichen Technologien implementiert wurde, kann man noch immer diese Modelle etc. entweder erneuern, anpassen oder zusätzlich mit „Prescriptive Analytics“ erweitern.
Was sind die künftigen Potenziale?
Konzeptionell betrachtet ist Big Data eigentlich nichts Neues außer einer Erweiterung der bereits etablierten Datenanalysetechniken und IT-Architektur. Wirklich revolutionär sind hingegen Technologien wie Spark oder Flink und die dahinter versteckten Streaming-Mechanismen. Die Verarbeitung von unstrukturierten Daten in Echtzeit ist die wahre Stärke dieser Systeme. Z.B. um Betrugsbekämpfung wirklich effizient zu machen, müssen außer strukturierten- auch viele quantitative unstrukturierten Daten wie Webtracking, Bewegungsdaten, Geodistanzen etc. in Betracht gezogen werden, die es in Echtzeit zu verarbeiten gilt. Um noch effizienter zu sein wird u.a. sogar Dateneingabezeit auf der Webseite etc. als Indizien zum Modell hinzugefügt, damit bei einer Online-Kreditvergabe Risiken für den Geldgeber minimiert werden können. Jedoch gilt die These, dass, je mehr quantitative Datenerhebungen stattfinden, desto Rechen- & Zeitaufwendiger werden die Echtzeit Analysen. Genau da steigen Big Data Technologien ein – denn es reicht nun mal nicht, den Betrüger 10 Minuten nach dem Betrug zu bemerken, während der Schaden schon entstanden ist.
Ebenso nützen dem Kunden alle technologischen Fortschritte nicht, wenn er vor einem Bankomat-Gerät steht, seine Karte zuhause vergessen hat und nicht mit Hilfe einer App am Smartphone einen (sofort)Kleinkredit in Echtzeit beantragen- bzw. ausbezahlt haben kann!
Nicht nur kundenspezifisch- sondern auch maschinell erzeugte Daten werden immer wichtiger und deshalb hat Big Data aus meiner Sicht ein sehr starker Synergieeffekt mit Industy 4.0 wenn wir in Zukunft mehr Optimierung, aber auch Automatisierung vorantreiben wollen. Es kann bspw. ein Flugzeugstriebwerk sein, welcher Echtzeit-Daten über Beschädigungen, Temperatur etc. liefert und somit zeitgleich kostenschonende & versicherungsrelevante Vorhersagen für den Betreiber erstellt werden können. Auch in der Forschung u.a. in der Astrophysik, Kosmologie spielen dazugehörigen Data Mining oder Analytics Verfahren eine immer größere Rolle, damit wir mit Hilfe der Daten unser Universum besser verstehen.
In Wahrheit steht die Menschheit in fast allen Bereichen der Wirtschaft & Forschung vor riesigen Herausforderungen und muss in einer sehr kurzlebigen- & informationsgetriebenen Zeit Erkenntnisse aus den Datenbergen gewinnen und sogar manchmal diese Erkenntnisse in Wissen ummünzen! Das Phänomen Big Data Analytics oder Data Science ist nur eine Antwort darauf, die versucht aus einer empirischen Ecke diese Fragestellungen zu klären und wird sich im Laufe der Zeit noch sehr optimieren bzw. verbessern.

Was sind die wichtigsten Trends im Bereich Big Data auf die man achten sollte?
Die richtige Revolution hat im Hintergrund mit der sog. Lambda-Architektur oder neuerlich auch Kappa-Architektur begonnen, in dem sich Unternehmen ganzheitliche Gedanken über ihr zukünftiges Daten-Ökosystem machen, um mehr Geschwindigkeit, Performance aber auch Vorhersagbarkeit zu erreichen. Daraus ergeben sich ganz neue Möglichkeiten und Geschäftsfelder für die Zukunft.
Abgesehen davon steht uns einer der wichtigsten Entwicklungen im Bereich Data Science bevor. Nämlich die sog. Data Science 2.0, also die Automatisierung von Datenanalyseschritte, Modellgestaltung und Testing. Das Phänomen kann in Kombination mit Clustern auch als „Big Data as a Service“ betrachtet werden, indem Rechenkapazität am Big Data Cluster von Großunternehmen einfach vermietet werden. Somit bekommen Klein- und Mittelbetriebe auch die Möglichkeit aus Big Data Analytics/Data Science zu profitieren, ohne in ein Data Lake zu investieren- oder einen ohnehin kaum verfügbaren Data Scientists anstellen zu müssen. Mit der zunehmenden Erkenntnisgewinnung aus den Stammdaten werden etliche explorative Schritte im Werdegang vieler Data Science Projekte in Zukunft nicht dieselbe Gewichtung haben wie gerade jetzt (70% des Aufwandes fließt in Data Cleaning, Preparation etc.). Dafür wird sich der Schwerpunkt viel mehr in „Multi-Modelling & Productionizing“ verlagern, um bessere Ergebnisse zu erzielen.
Data Science 2.0 hin oder her, Big Data wird in den nächsten Jahren weiterhin topaktuell sein und es zeichnet bereits jetzt eine Trendwende in Investitionen der Unternehmen in verwandten Technologien & Konzepten ab, v.a. weil das Thema in Kombination mit Digitalisierung & Industry 4.0 unsere Welt mehr denn je prägen wird. In diesem Zusammenhang muss auch gesagt werden, dass nicht alles was die EU von sich gibt auch negativ, sondern immer wieder sogar goldrichtig ist! Die DSGVO (Europaweite Datenschutzgrundverordnung ab Mai 2018) gibt den EU Mitgliedern eine einzigartige Chance einer zentralen Regelung für alle Datenschutzmaßnahmen, alle nationalen Datenschutzregelungen, die kaum unterschiedlicher sein könnten und zum größten Teil überholt sind. Das ermöglicht der Wirtschaft, Wissenschaft etc. Datensammlung & Verarbeitung, aber auch sonstige digitalisierungsrelevante Innovationen in geordneten Bahnen voranzutreiben und letzten Endes berechtigte Interessen der Konsumenten zu schützen. Die Einhaltung der Datenschutz Mechanismen ist aus meiner Sicht unverzichtbar, weil eine fahrlässige Vernachlässigung laut der DSGVO zur 20.000.000,- oder (wenn höher) 4 % des Jahresumsatzes kosten kann! Also bedarf es einer richtigen Strategie rund um aller Innovationsziele im Big Data Bereich – und keines Falls sollte dabei die Datenschutzmaßnahmen vernachlässigt werden.
Viele weitsichtige Unternehmen nützen nun diese Chance, auch u.a. die Versäumnisse in Data Security, Governance, Data Dictionary, Metadata Management oder sogar Lineage aufzuholen, indem sie kluge- & strategische Investitionen tätigen. In Kombination mit Big Data Analytics/Data Science erfüllt so ein Daten-Ökosystem alle Anforderungen der kommenden Jahre, um Fähigkeiten in Machine Learning oder Predective Analytics zu steigern. Aus meiner Sicht werden letztendlich genau diese Innovationsvorsprünge wichtig sein, um weiterhin profitable Geschäfte zu betreiben und zeitgleich die digitale Wende zu meistern.